The brief said library. The product is the filed authority list.
CLMS supports barristers and chambers staff in preparing a List of Authorities: the document filed before a court hearing, setting out every case, piece of legislation, and book the practitioner intends to cite, formatted to the relevant court's requirements.
The brief arrived as a chambers library management system. The move that decided the project was a reframe: the library is not the destination, it is the input. The document filed with the court, the authority list itself, is the product. Catalogue, availability, and loan state matter because they feed that filing, not because the library is the home surface.
The filed authority list is also where the liability sits. Under Rule 24 of the Barristers' Rules, the barrister carries one hundred percent of the responsibility for what they file: every citation, every pinpoint, every formatting choice measured against the court's requirements. Designing around the filed artefact meant designing around the thing that actually carries risk, and that single shift decided every Phase 1 decision downstream.
Two roles, one filed document, strict court rules.
Two distinct roles in the chambers we worked with. Barristers focus on legal strategy, drafting, and advocacy, the work that requires their judgement. Chambers staff handle administration, coordination, and practice support, including, in this case, the catalogue and library operations that feed the authority lists. The roles are not the same everywhere in Australian chambers; they vary by state and by chambers, but in our design-partner cohort this split was consistent.
The problem. Citation formatting is still largely manual. Filing requirements differ across courts. AGLC4 is detailed and strict. Even experienced practitioners lose time to formatting rather than legal judgement. That is the gap the product is built to close.
Developed in close collaboration with Michael Green (practising barrister and primary stakeholder) and Sean Simpson (librarian SME) at BarNet OpenLaw, the team at BarNet (the company behind JADE, Australia's most-used legal database) building authority-list and chambers tools alongside the database itself. The Phase 1 interface shown below is a high-fidelity, mock-data prototype built around the spec; production API integration, real JADE wiring, authentication, and server-side privacy enforcement sit with Open Law engineering.
Fragmented authority preparation, compliance risk surfacing too late.
Before CLMS, preparing an Authority List for a hearing meant coordinating several surfaces that nothing tied together. Each barrister and the chambers staff supporting them worked around the gaps individually, and the document the court actually saw was the last place the work was assembled. The pain was the coordination, not any single tool.
- 01Authority sources, citation rules, and court templates lived in separate tools, with the document editor as a fourth surface.
- 02AGLC4 formatting and court-specific filing requirements lived outside the editor, as references the barrister consulted manually.
- 03Compliance issues surfaced at the final review the day before filing, creating recurring late-stage pressure on every list.
- 04Barristers and chambers staff coordinated source materials and library holdings through messages and side channels, not through a shared surface.
- 01Keep authority research, citation work, and the court-ready output inside one workflow.
- 02Make AGLC4 rules and court templates visible while drafting, not after.
- 03Flag compliance issues at the point of entry, not at the final review.
- 04Design around the filed artefact: the court-ready document is the primary surface, the editor serves it.
- 05Support the barrister and chambers-staff handoff through shared catalogue data, not through messages.
What I owned, and what sat with others.
What I owned. The title was Product Designer, but the role spanned research, architecture, design, and the build: the phased product architecture, Phase 1 product slice, information architecture across barrister and clerk workflows, court-template research, authority-list editor design, clerk library operations, the Phase 1 frontend implementation on React 19 + Tailwind 4 (custom atomic-design component library, Storybook-documented), and the Phase 2 AI spec.
What sat with others. Open Law engineering owns production backend integration, real JADE API wiring, authentication, server-side privacy enforcement, email reminders, and deployment. Michael Green and Sean Simpson provided domain validation; they confirmed accuracy, not design.
Discovery before design. Sketches once the domain made sense.
Before committing to a design I ran discovery and co-design sessions with the barrister and librarian SMEs, with no preset designs to defend. The goal was to learn the domain first: what AGLC4 requires, what a List of Authorities actually is, why Rule 24 matters, and how Australian chambers really operate. These were teaching sessions, not validation calls.
Two insights from that learning drove everything that followed. First, an authority list is not a database export. It is a court-ready document, and AGLC4 detail is genuinely strict. Second, in the chambers we partnered with, the two roles measure success against different things. The barrister cares about the filed output. The library and admin side cares about the system underneath. Same product surface, different definitions of good.
Only then did the sketches come out: simple and low-fidelity, used as conversation tools rather than designs to approve. With the domain understood, the structure could be shaped fast and corrected inside the same session, instead of being defended after the fact.
Three phases, sequenced. AI waits until the workflow is adopted.
The hardest call on this project was structural. The temptation was to ship AI in Phase 1, since that is the obvious product story for legal tools right now. I made the call to wait. The reasoning: if barristers are not already building authority lists in the system, AI suggestion has nothing to attach to. AI is a feature on top of a workflow; without the workflow, the AI feature has no home.
The reframe I used with Michael: "AI without adoption is a demo. AI on top of an adopted workflow is a product." He agreed in the first session. The phased structure also let us ship something validatable in three months instead of debating an unvalidated AI feature for six. Phase 1 ships without AI. Phase 2 layers AI on top, only after Phase 1 adoption is validated.
To hit the three-month window, I cut hard: no AI suggestion, no matter workspace, no portable brief. Each became a Phase 2 or 3 spec entry, not a backlog. The Phase 1 surface that shipped is the smallest version that proves the workflow, the trust posture, and the cross-role data layer.
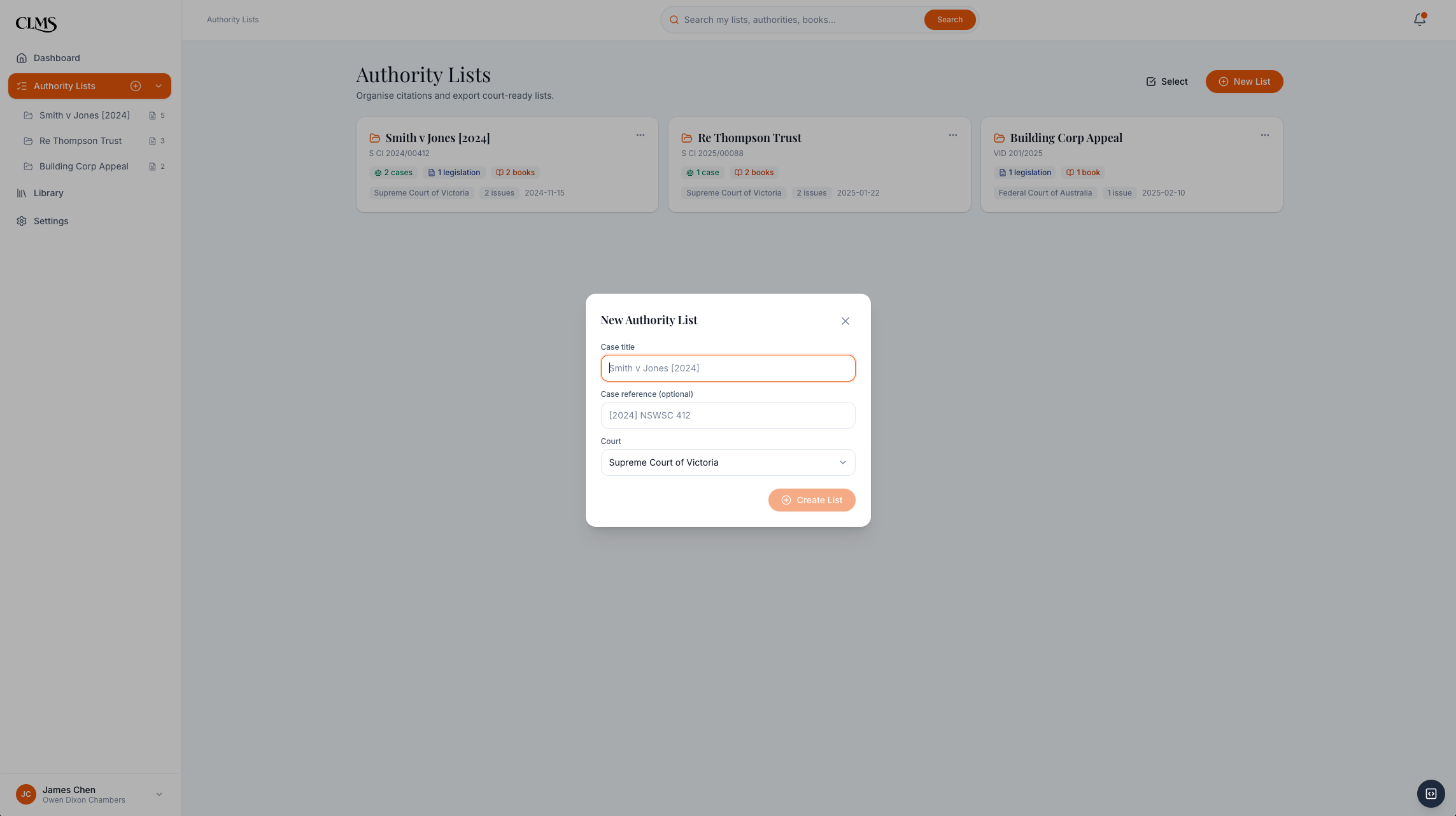
Authority Lists + Library Management
The spec split Phase 1 into two daily loops. Barristers search JADE-style legal results and the chambers catalogue, add authorities, enter pinpoints, classify parts, preview the court document, and export. Clerks set up the catalogue, track loans, process requests, and keep availability accurate.
The hard product decision was not "what AI can do later." It was what must exist before AI is allowed anywhere near a court filing workflow.
Private authority lists
Each barrister's research strategy stays isolated.
Court-ready output
AGLC4 preview, part structure, pinpoints, and export path.
Shared catalogue data
Clerk-managed availability drives barrister decisions.
Logged requests
Loan and recall requests become trackable work, not buried messages.
Mapping the system before the screens
I worked the full IA on paper before touching Figma. Two roles, two navigation structures: barrister with five items, clerk with seven. Two daily flows: barrister moves Find → Cite → Track, clerk moves Track → Scan → Manage. And five cross-role interactions where the two flows meet.
The most critical of those is the shared catalogue interaction. A barrister adds an uncatalogued book to their list; that has to surface to the clerk as a catalogue task; that has to come back to the barrister as a resolved citation. If that intersection does not work, nothing else does. The product fails as a single system if those five intersections are not designed first, so I mapped them before any screen.
Desk research on comparable legal systems and discussions with Michael surfaced edge cases around uncatalogued materials, citation gaps, and the danger of exposing another barrister's research strategy. Multi-brief barristers, the other recurring edge case, became the case for the Phase 3 matter workspace. Those constraints shaped Phase 1 before the first screen was built.
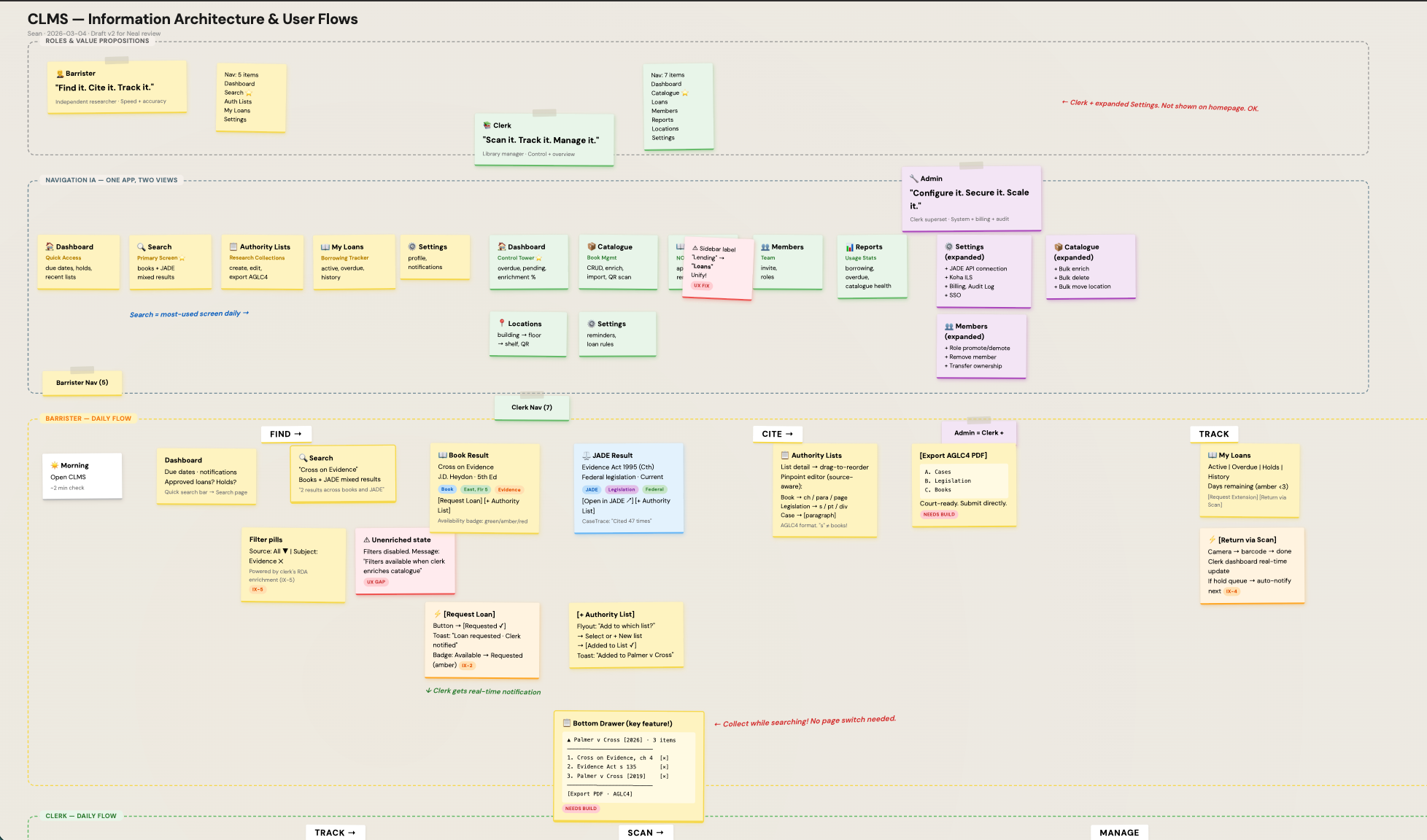
Two roles, two navigation structures, and where they meet. Barrister and clerk use the same product but live in different halves of it.
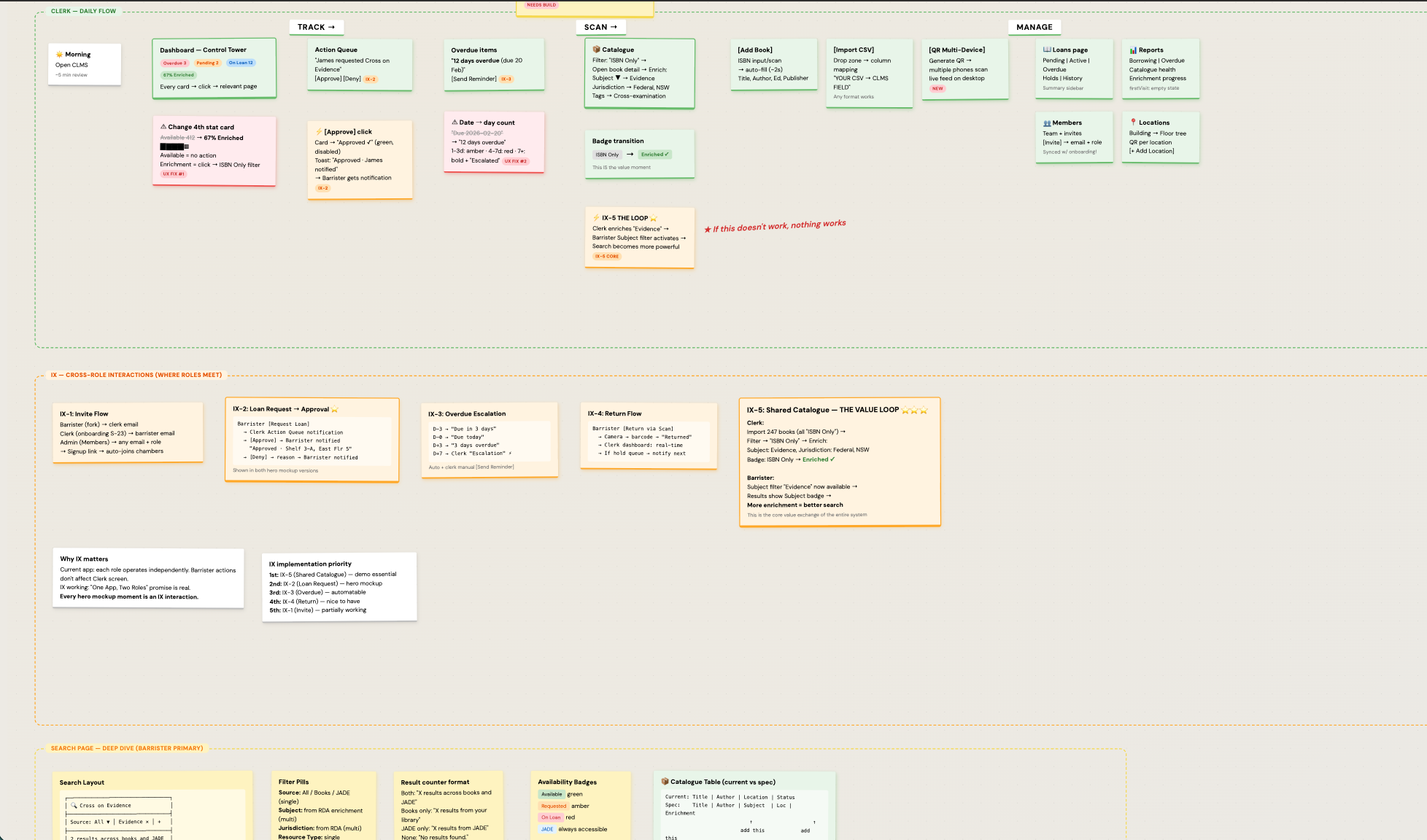
The shared catalogue is the connection point. If availability is stale, the barrister workflow breaks.
Five decisions came out of the mapping.
Each one resolves a specific tension the cross-role mapping exposed, and together they set the Phase 1 product structure. The interface those decisions produced comes after them.
The authority list is the product, not the library.
The brief came in as "chambers library management system." After the SME sessions I reframed it: the library is the input, the authority list filed with the court is the product. That single reframe decided every Phase 1 decision downstream. Editor and live court preview take the centre of the screen; the library sits alongside, feeding the filing with availability and metadata rather than competing for the home surface.
Manual input is not an edge case. If a barrister needs an uncatalogued textbook, they must still be able to use it in the list. The system flags the gap instead of blocking the workflow.
AGLC compliance from court templates, not just a style guide
I researched the actual filing templates from four courts: VIC Supreme Court (Court of Appeal), NSW Supreme Court (Court of Appeal), Federal Court (GPN-AUTH), and the High Court of Australia. Each has different requirements.
"List of Authorities" vs "Table of Authorities." Part A/B/C structures with court-specific wording. Continuous numbering across parts. Party name formatting. AGLC4 italicisation rules. These details determine whether the final document feels court-ready or like another draft to fix.
This is a rules problem, not an AI problem. AGLC4 has fixed criteria; each court has a structured template; most citation errors are detectable against deterministic rules. That is why Phase 1 leaves AI out entirely. The system can do useful, accurate work without ever generating a citation, by treating the templates as a validation surface rather than as a style guide.
Underneath, this is a multi-variant form system with court-specific validation: one structured data model, four court-specific render variants, and a template engine that swaps headers, numbering, and party-name formatting per selection. It is the part of this work that maps most directly to forms, questionnaires, and document-automation interfaces. I sat with engineering early to validate the schema before the UI froze, so the template engine and the selector evolved together rather than in conflict.
Uncatalogued books surface as inline flags, not blockers.
When a barrister adds a book that is not in the chambers catalogue, the editor accepts the incomplete entry with an inline error flag instead of blocking the workflow with "add this book first." Errors are surfaced where they can be acted on (the editor), not buried in the document output.
The unresolved item simultaneously surfaces to the clerk's catalogue workflow as a task. The barrister never blocks; the clerk never has to ask "what does this barrister need?" The two workflows feed each other.
The chambers library: clerk's responsibility, barrister's working surface.
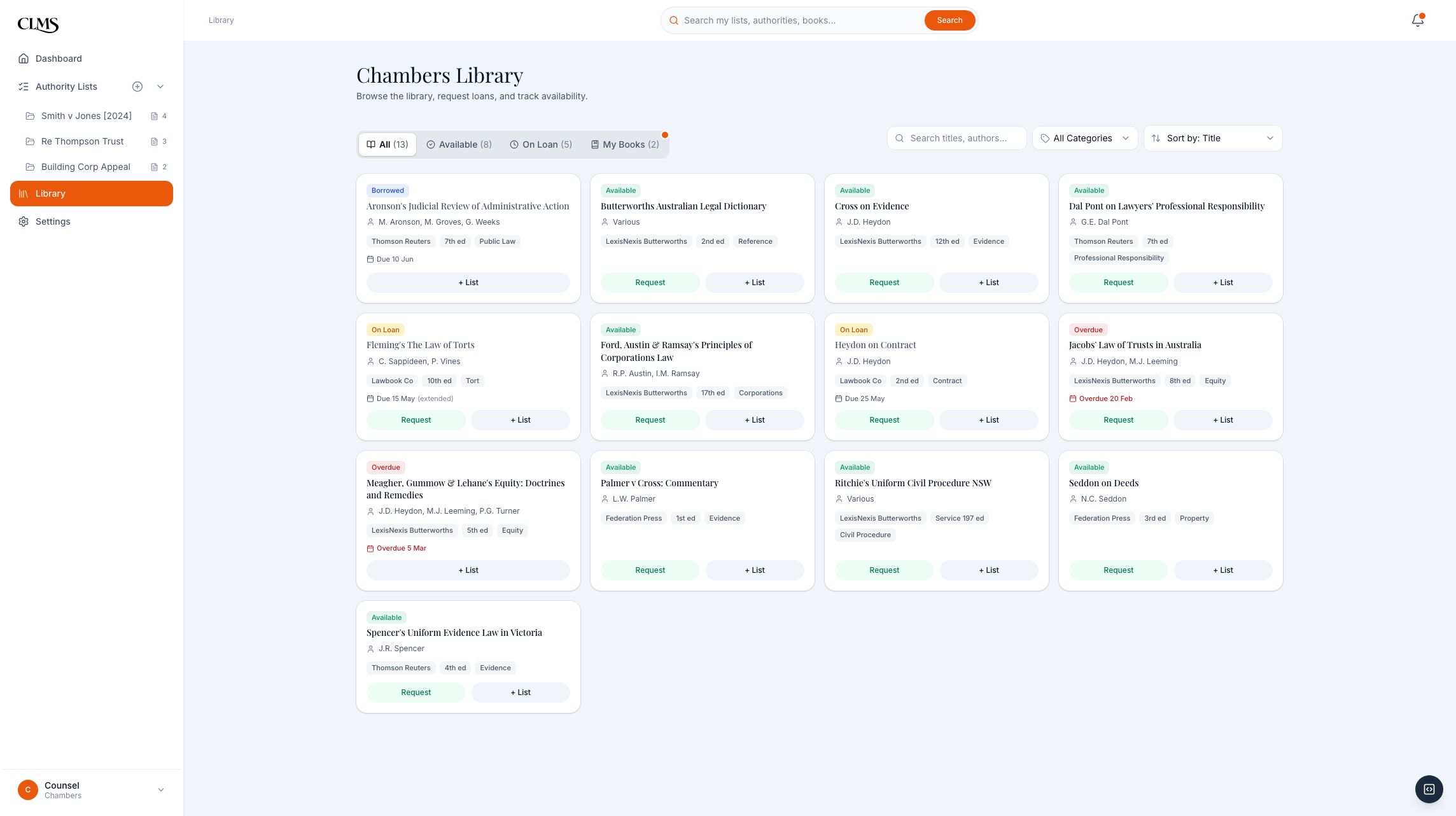
A public-library ILS is too heavy for a chambers clerk, while a spreadsheet does not connect to barrister research. CLMS only needed the operations that make the legal workflow work: catalogue, availability, loans, requests, and clean metadata. Owned by the clerk, browsable by the barrister, with add-direct from research.
The clerk's job is not to become a librarian. It is to make the shared collection reliable enough that barristers can trust what they see during research. Same product surface, two roles, one shared data layer.
List privacy is not a feature to add later. It is an architectural constraint from day one.
Barristers in the same chambers can end up on opposing sides of the same matter. Under the cab-rank rule and the way chambers operate, it is a real possibility, and the SMEs flagged it early. An authority list reveals legal strategy: which cases the barrister thinks are persuasive, which they need to distinguish. If one barrister can see another's list for the same matter, the system creates a conflict of interest.
The spec treats list privacy as a prerequisite for trust: no shared lists, no popular-authority leaderboards, no aggregate usage patterns that expose strategy in a small chambers. It shapes the data model: who can access what. It shapes the chambers library: barristers see shared resources, never other people's lists. The clerk sees library data only; individual research stays isolated and requires server-side enforcement in production.
Identifying this early prevented a structural redesign later. If we had built sharing first and added privacy as a permission layer, we would have rebuilt half the system. That kind of decision is hard to demo in screenshots, but it is the one that made the rest of the architecture possible.
Prototype testing sharpened the access model. Barristers needed to know whether a book was available and whether they could request a recall; they did not need another barrister's name attached to the card. The iteration rule became simple: availability is shared, borrower identity is clerk-facing.
List privacy is the first of two architectural constraints I treated as foundational. The second, AI safety under Rule 24, shapes Phase 2 and is covered below.
Privacy is not a static restriction; it is a design lens. It does not block AI from the library; it blocks one specific class of features. Anything reading from shared catalogue data is fine; anything reading from cross-user borrowing patterns is not. The same lens lets Phase 2 add AI on the JADE side without re-asking the privacy question, and decides which future library or matter-level AI features the architecture admits.
The surface those five decisions produced.
Two roles, one product. The barrister side builds the authority list and the court-ready filing; the clerk side keeps the catalogue and loans reliable enough to trust. The screens below walk both, and the cross-role loop where they meet.
From research to court-ready list
The barrister side had two paths to the same output. Fresh research starts with search and add-to-list. Repeat matters start from a saved authority list that can be duplicated, modified, and re-exported. Both paths end in the same court-ready preview.
The key was keeping the manual workflow fast enough to earn trust before introducing AI: inline pinpoints, part tags, drag reorder, availability status, and a live AGLC4 preview.
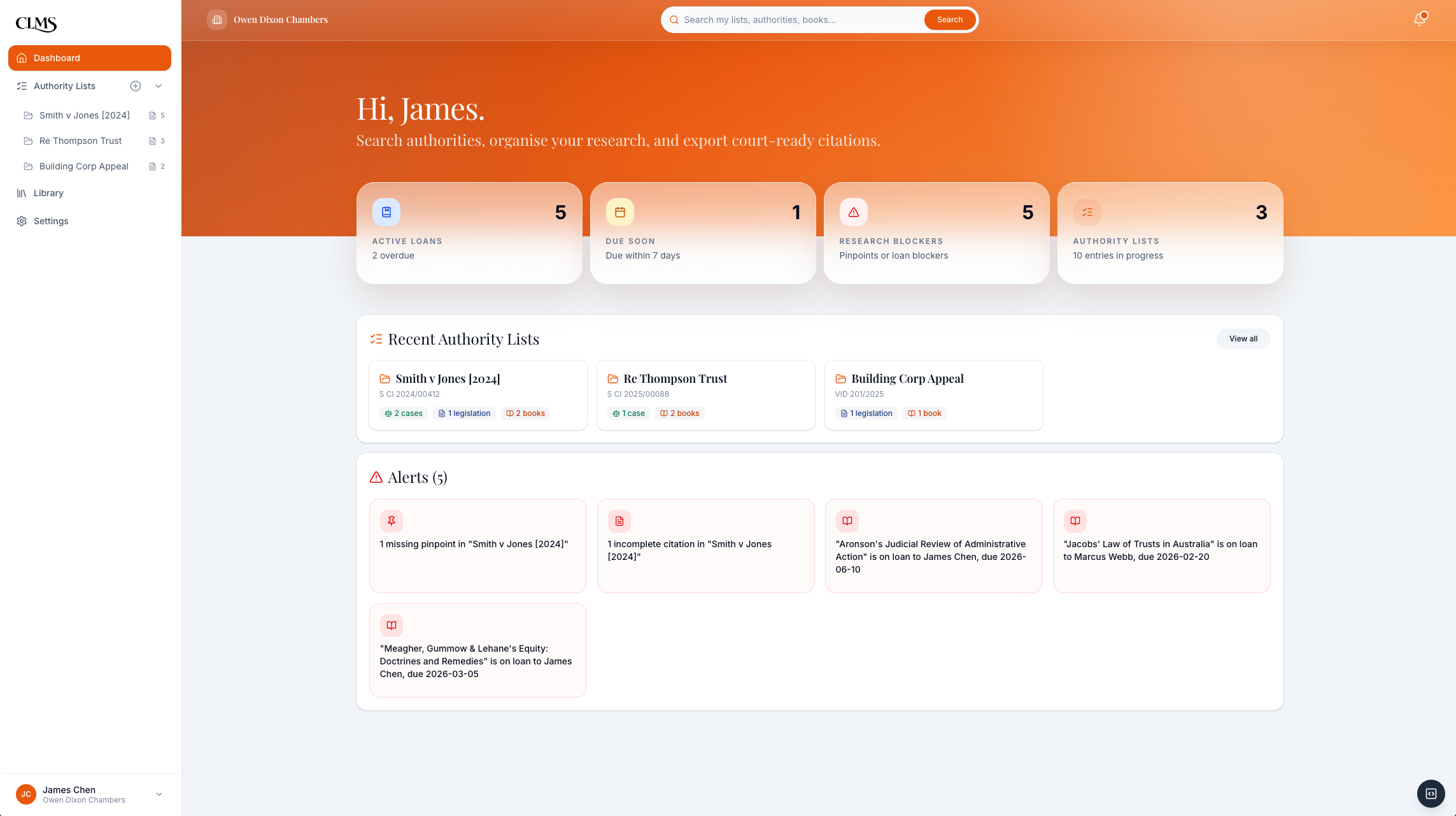
Barrister dashboard: recent authority lists, research blockers, active loans, and due-soon warnings surfaced together.
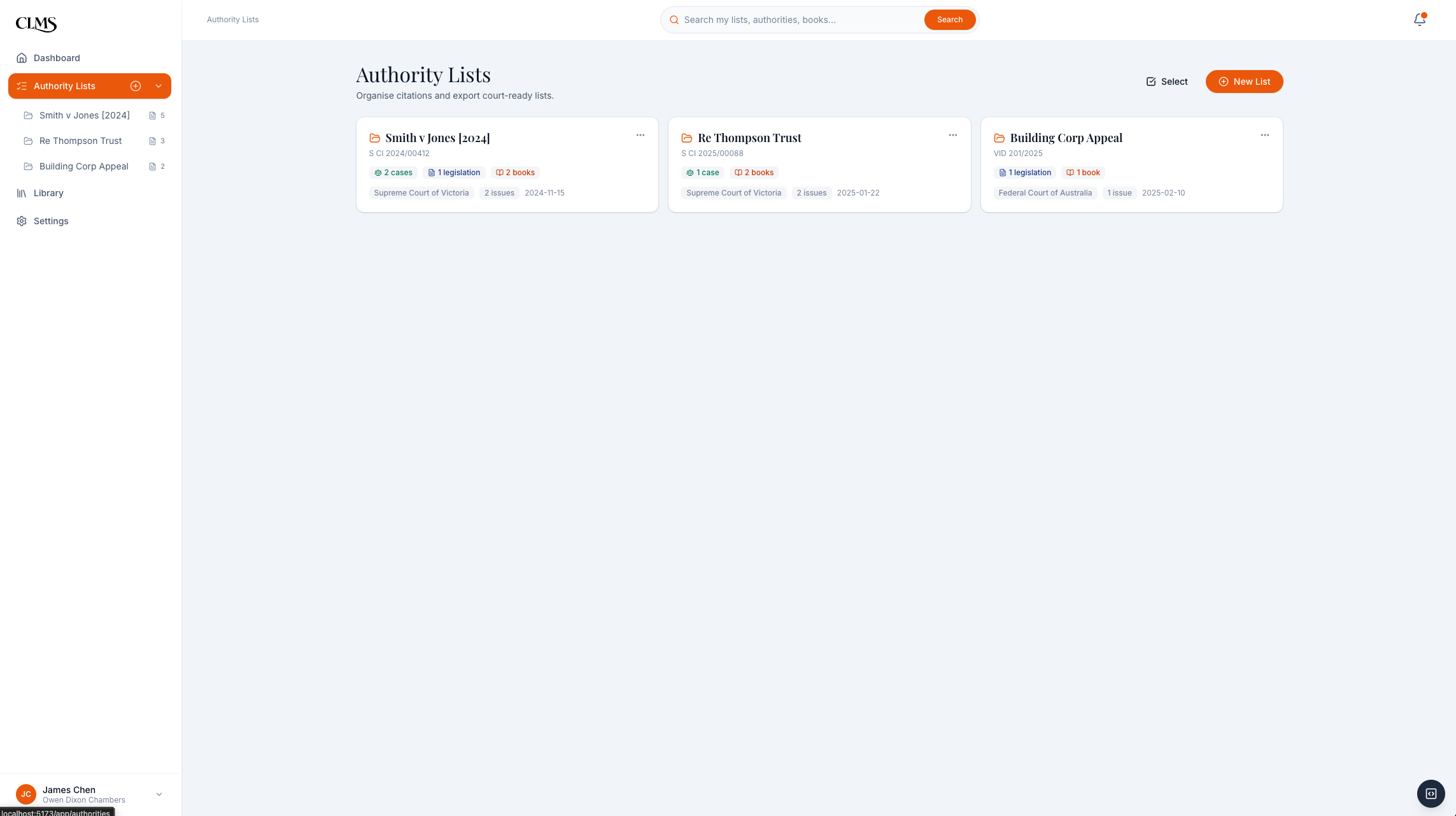
Past list reuse: saved authority lists become a personal research library the barrister can duplicate and adapt.
Court template selection sets the structure before any authorities are added.
Book results can be added directly into an authority list, keeping research and citation work together.
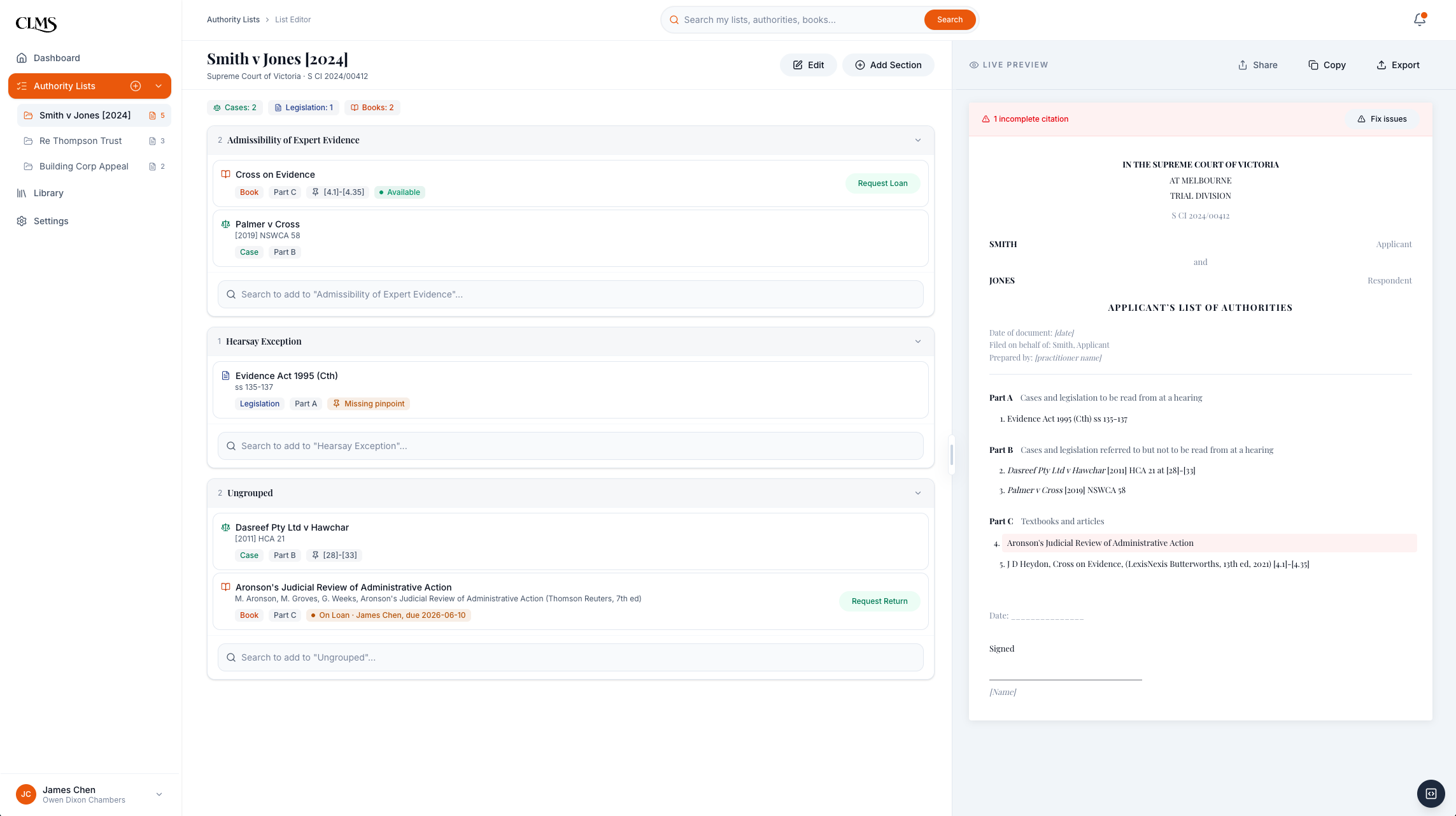
Authority list editor: editor on the left, live court-formatted preview on the right. The preview takes half the screen because the court template is the product the barrister is building.
The reframe shows up in the layout.
Left side is the editor: search JADE, add with one action, see flagged errors inline. Right side is the live court-formatted preview: VIC Supreme Court template, Part A/B/C structure, AGLC4 italicisation, party names formatted, signature block at the bottom.
The preview takes up half the screen. That is deliberate. Barristers care about the output, not the input. Hiding the preview behind a button would have hidden the actual product. The library sits in the sidebar, accessible but not the home.
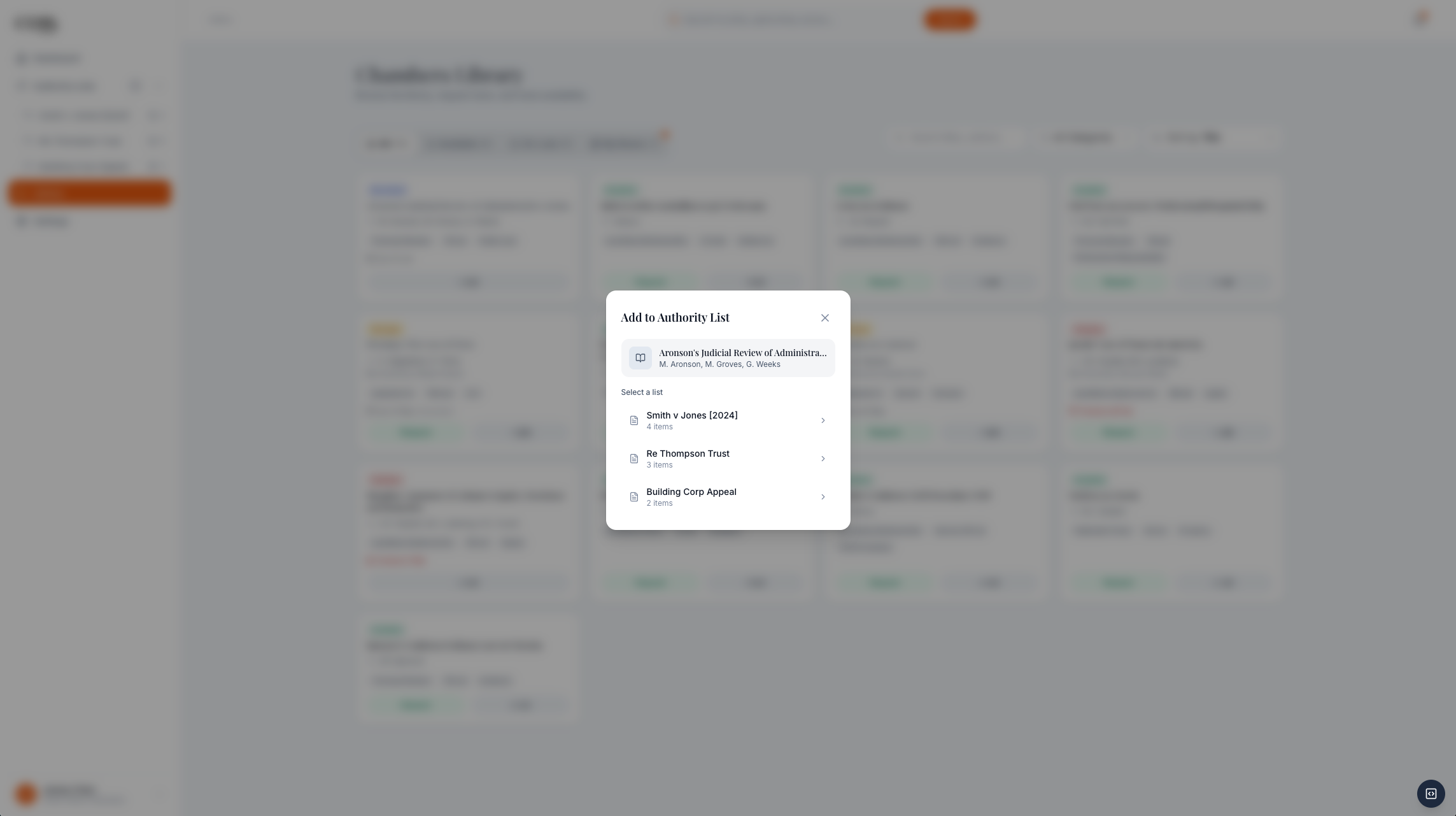
Book availability is visible before the barrister leaves the research flow.
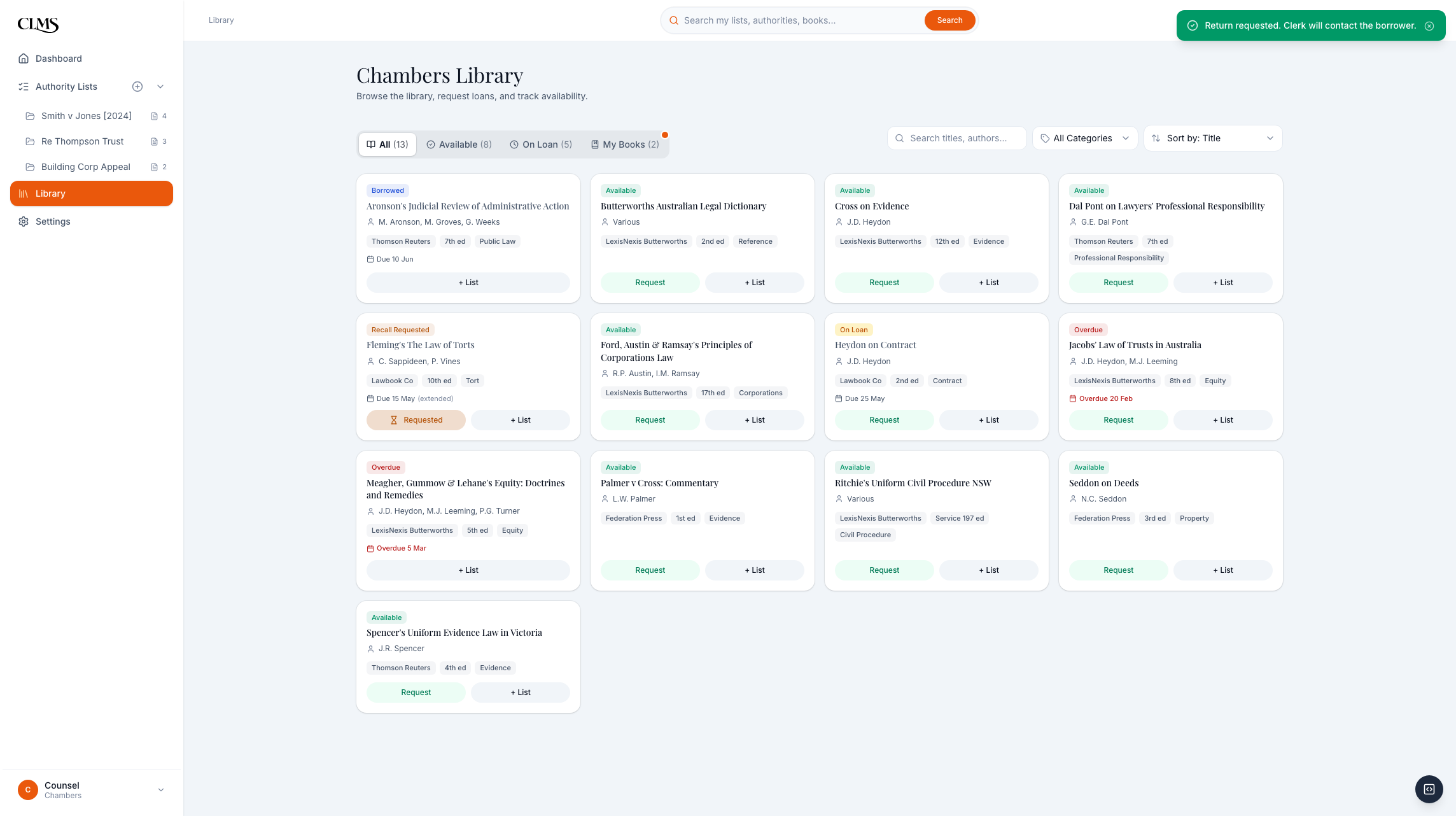
On-loan books create a clerk-mediated return request, not peer-to-peer pressure between barristers.
The clerk is the data gatekeeper
The spec made the clerk role non-negotiable. If the clerk does not maintain the catalogue and loans, the barrister side becomes unreliable: books appear available when they are gone, uncatalogued titles pile up, and requests disappear into message threads.
I designed the clerk side around setup speed and daily triage: import or scan the first books, process requests, track loans, mark returns, and improve metadata over time.
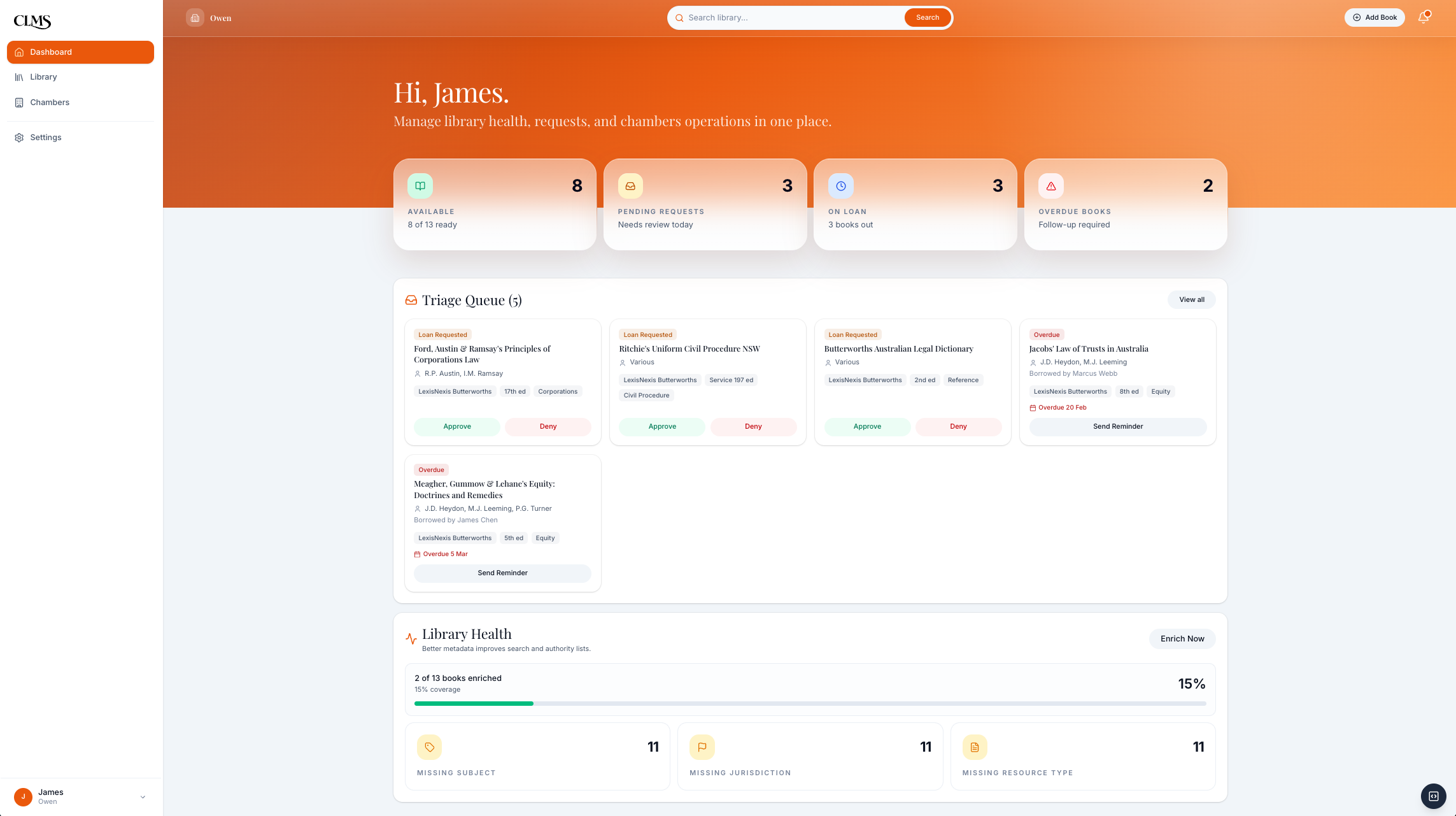
Clerk dashboard: pending requests, overdue books, active loans, and library health in one daily triage view.
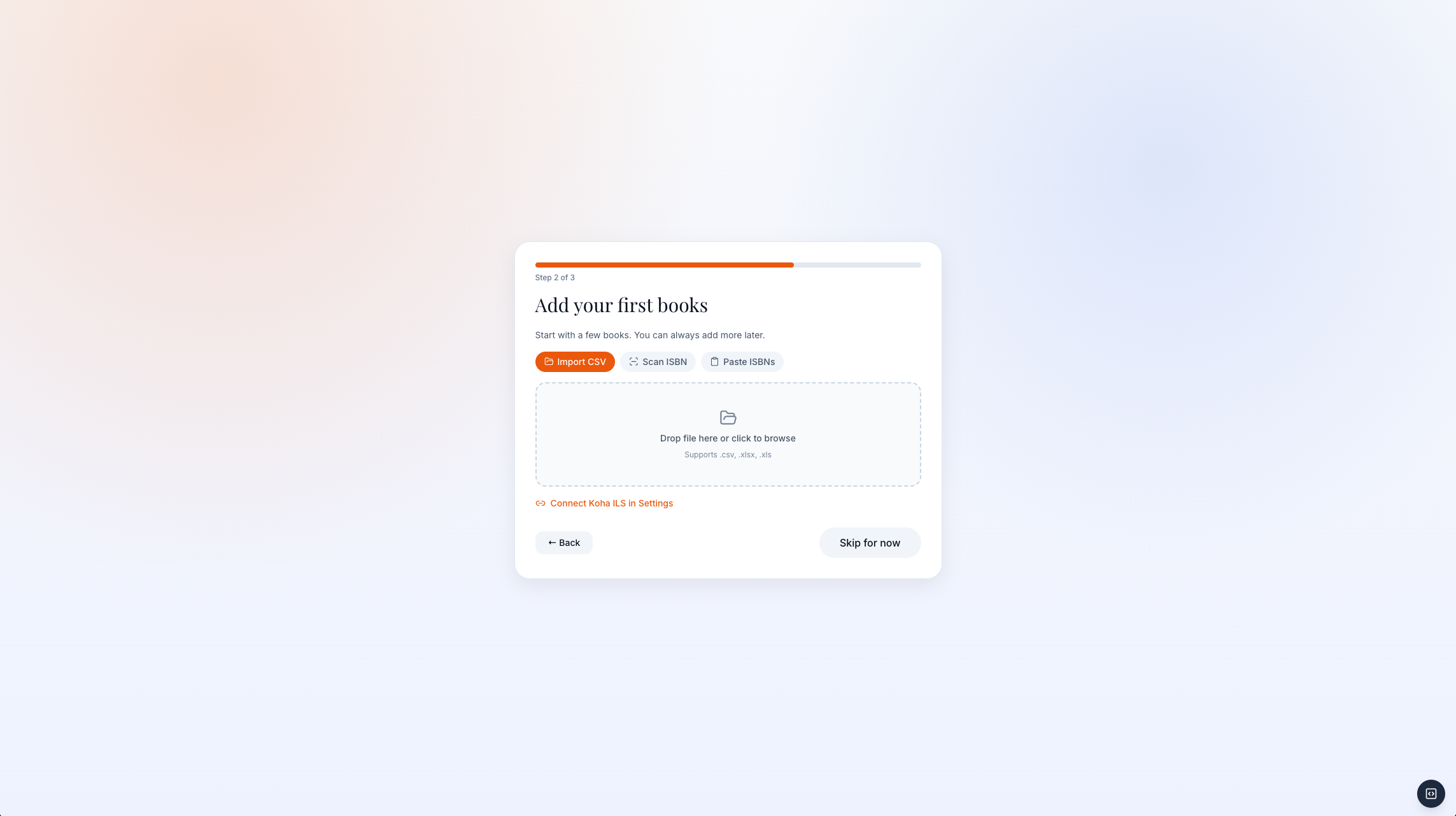
Setup reduces the biggest adoption barrier: getting the first catalogue into CLMS.
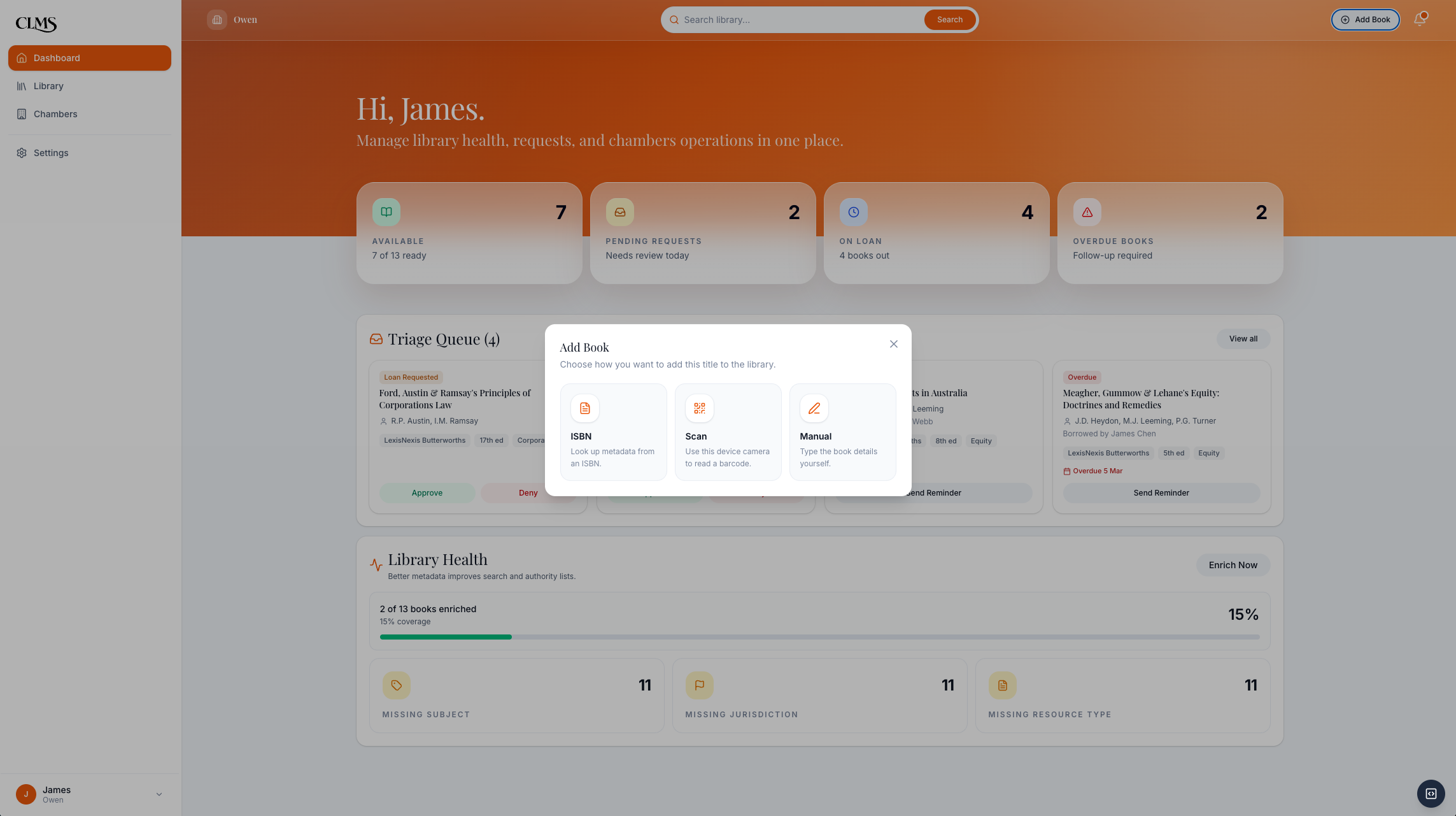
Three intake paths support real clerk habits: CSV import, ISBN scan, or manual entry.
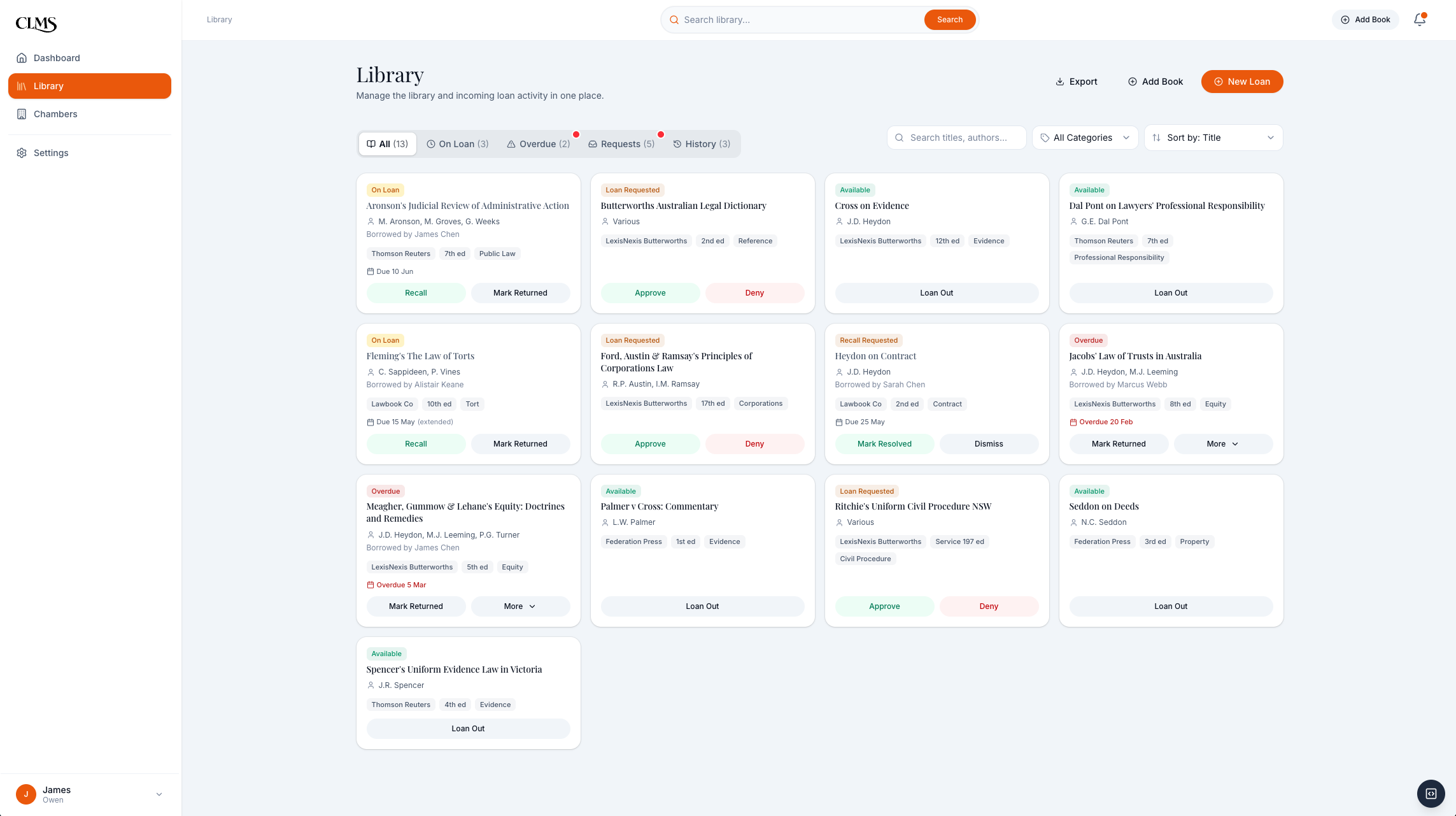
Library management: requests, recalls, overdue items, check-outs, returns, and export from one view.
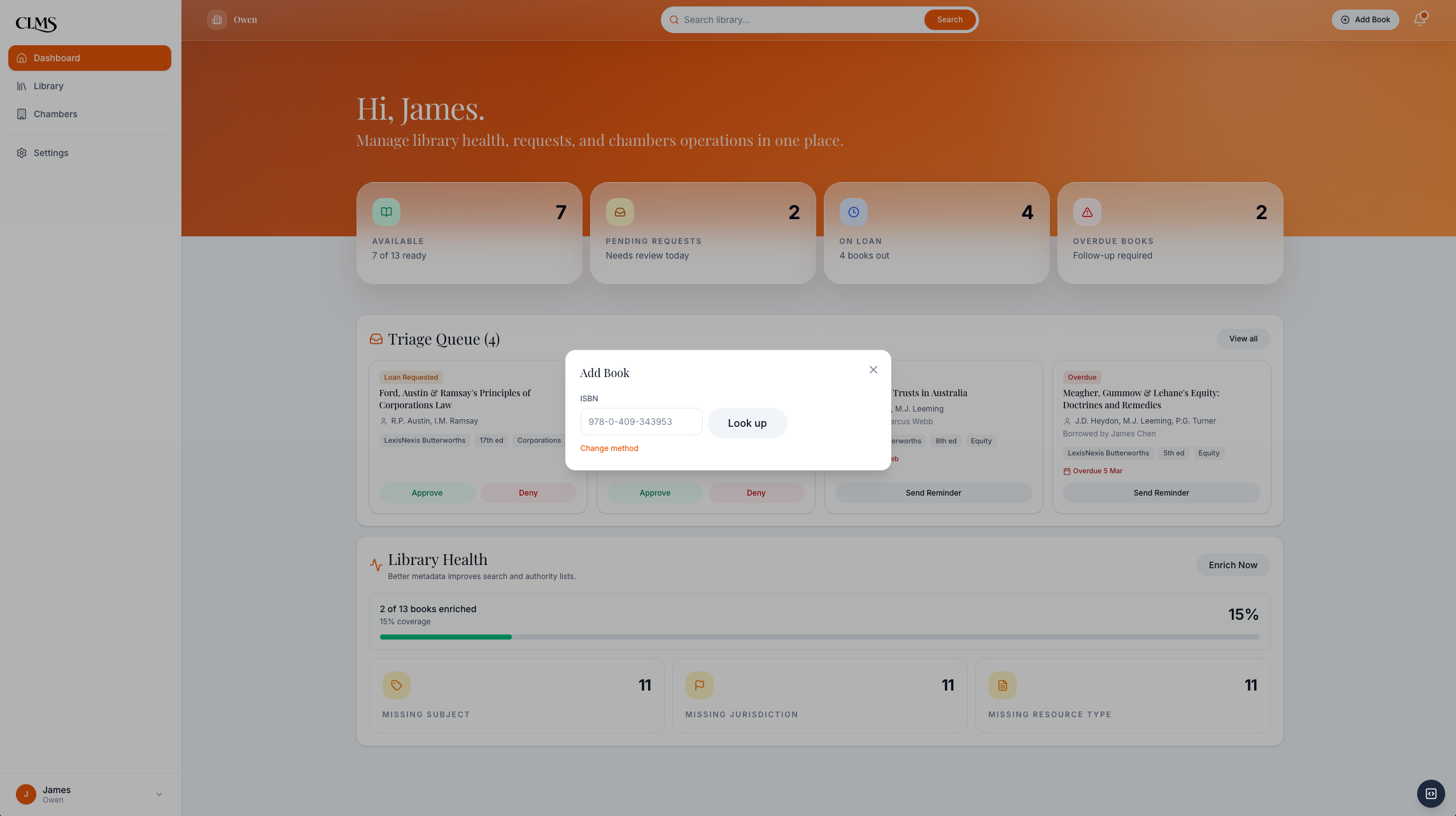
ISBN intake keeps single-book cataloguing quick when the clerk is adding or correcting a record.
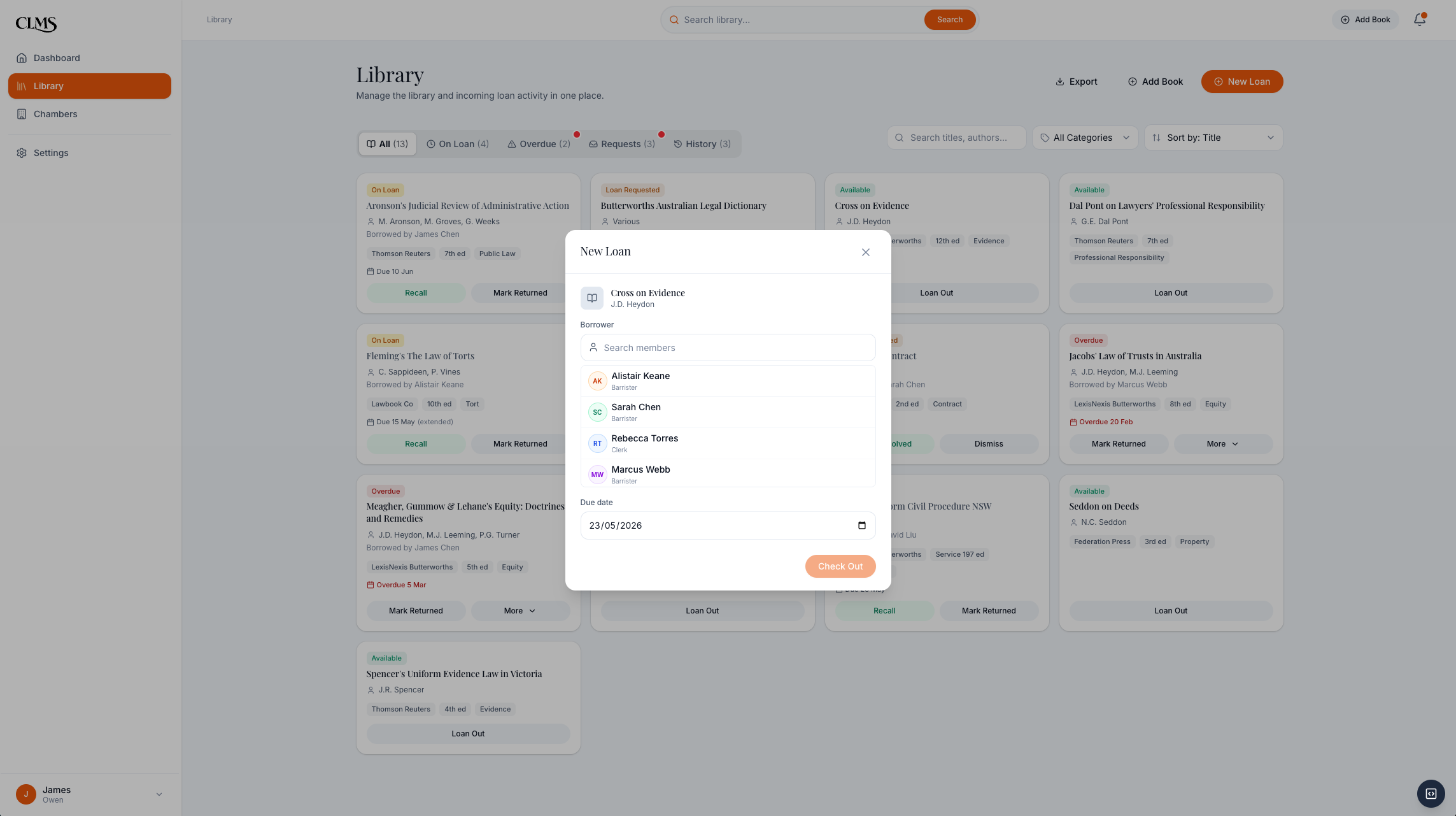
The check-out flow answers the clerk's daily question: who has this book, and when is it due?
Barrister requests become clerk triage. Clerk updates become barrister availability.
Phase 1 is only coherent if both roles close the loop. A barrister can request a book or a return without leaving the research surface. The clerk sees that request with the title, requester, borrower, and due date already attached. Once the clerk approves, recalls, or marks a return, the availability state becomes useful again for every barrister.
This is the real system value: not another list builder, and not another library catalogue, but the connection between court preparation and chambers operations.
The library piece is not decoration. Barristers do not just borrow textbooks; they consult them to verify the proposition, the pinpoint, and the context before the citation reaches the filing. The same Rule 24 logic that applies to cases applies to books: a misquoted textbook is the book-side version of a fabricated case. Specialist legal texts are expensive enough that chambers pool them, which is why the catalogue and the authority list have to share one product surface rather than two.
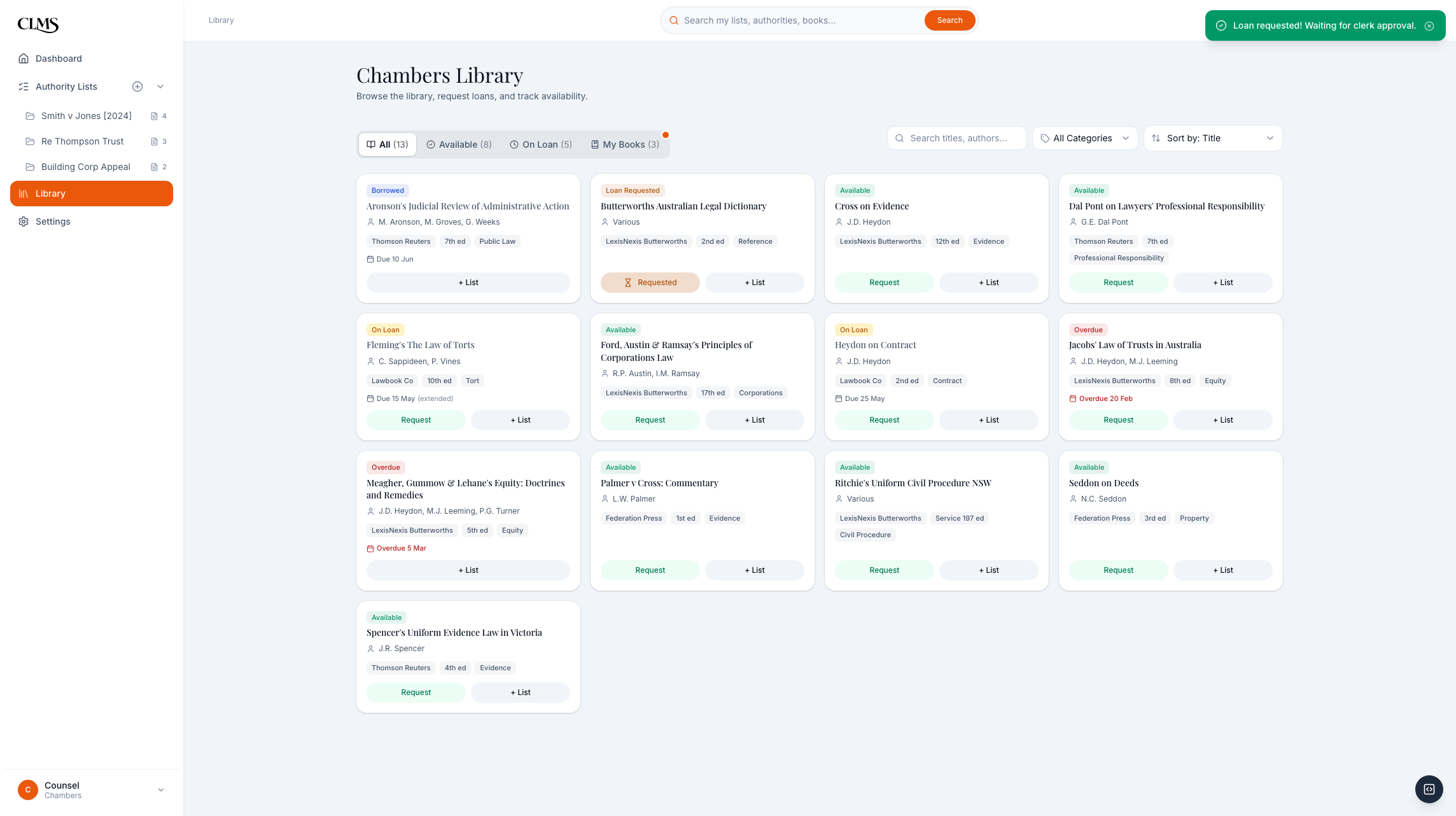
Barrister side: a book request is logged with context instead of disappearing into text messages.
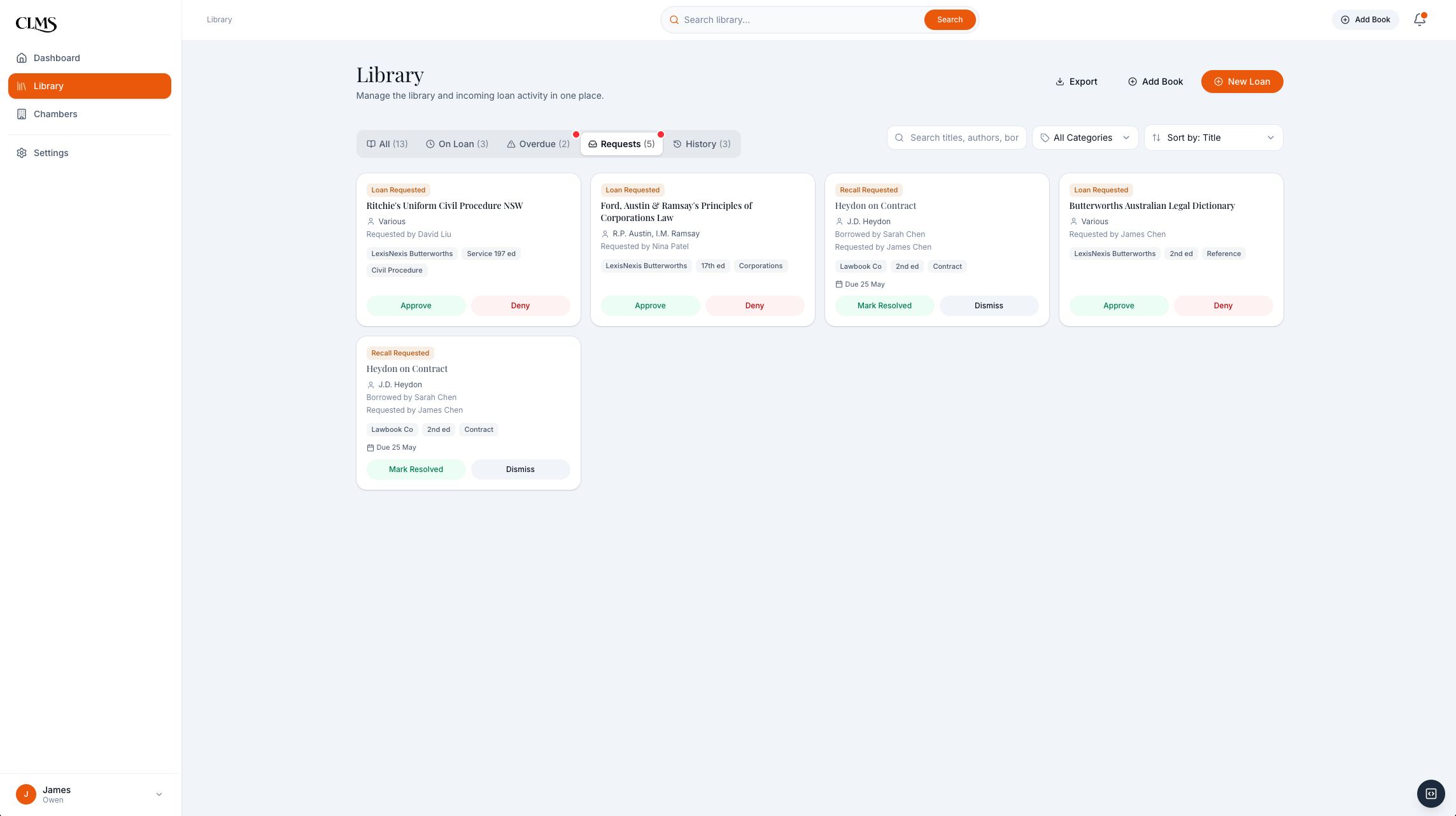
Clerk side: the request lands in the triage queue with the actions the clerk actually controls.
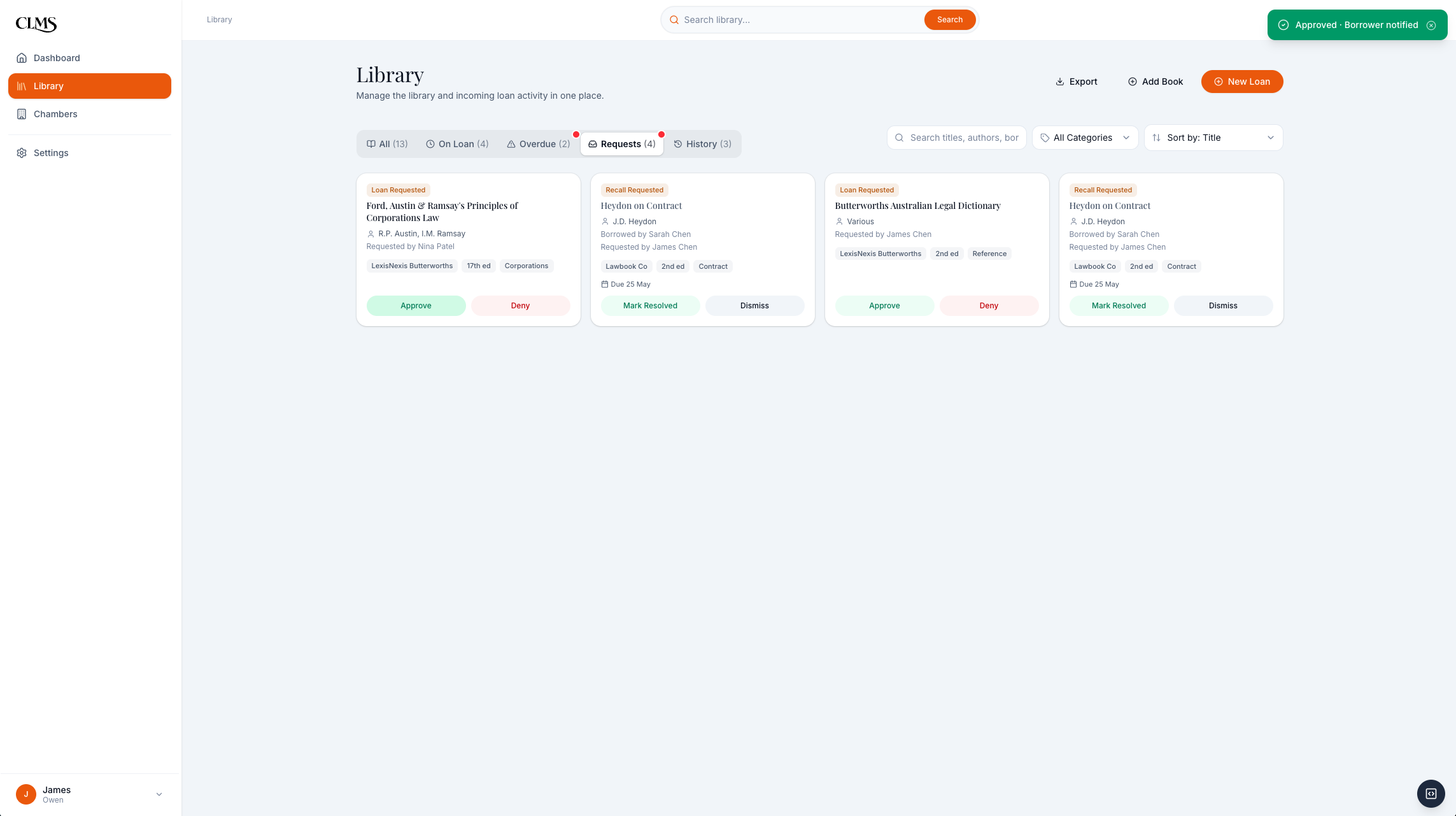
After approval, availability updates for barristers; borrower attribution remains clerk-facing because the catalogue is the operational source of truth.
A custom Tailwind component library, built to scale with the product.
Phase 1 was built on React 19 + Tailwind 4 + Vite, with a custom component library structured in atomic design layers: atoms, molecules, organisms, templates, pages. Ninety-one components in total, twenty-seven documented in Storybook so the next designer or engineer on the project can read patterns without reading my code.
The Tailwind config is token-driven. Brand colours, radii, typography, and shadows are CSS variables (--color-brand, --radius-hero, --shadow-metric), not hard-coded values. Every consumer reads from tokens, so a future redesign or a swap to a Radix-based primitive set does not require rewriting components.
My default is ShadCN as the primitive layer, customisation minimal, ship. CLMS is the exception, not the rule. This is a design-partner prototype where patterns were still moving (authority list editor, inline pinpoint input, court-template preview), so I built a thin custom atomic layer on Tailwind tokens instead of committing to a primitive set too early. The token layer means swapping to ShadCN-Radix later is a config change at the atom level, not a component rewrite. The atomic structure plus token layer is what the next team builds on as the product extends to new courts and new AI surfaces.
Task Signal
A pre-launch walkthrough with six barristers from Open Law and Michael's chambers produced a directional signal: 5 of 6 generated a court-ready authority list on their first attempt. The sixth needed assistance finding the court-template selector. The baseline for the same task, manual formatting against a court template, is around 25 minutes per list, per the SME group's own estimate.
Privacy Iteration
The strongest qualitative finding was not about speed. It was about disclosure. On-loan status helped barristers decide what to do next, but borrower names created unnecessary chambers visibility. I revised the access model so barristers see availability and request actions, while clerks retain borrower/requester attribution for operational follow-up.
These are pre-launch testing signals against a small cohort, not production metrics.
The Phase 2 spec rests on the Phase 1 foundations.
The AI features below are not roadmap items. They are downstream of the privacy model, the catalogue, the citation surface, and the export path Phase 1 established. The Phase 2 spec is the architecture continuing.
Phased rollout. Phase 1 establishes the trusted manual workflow before AI is introduced.
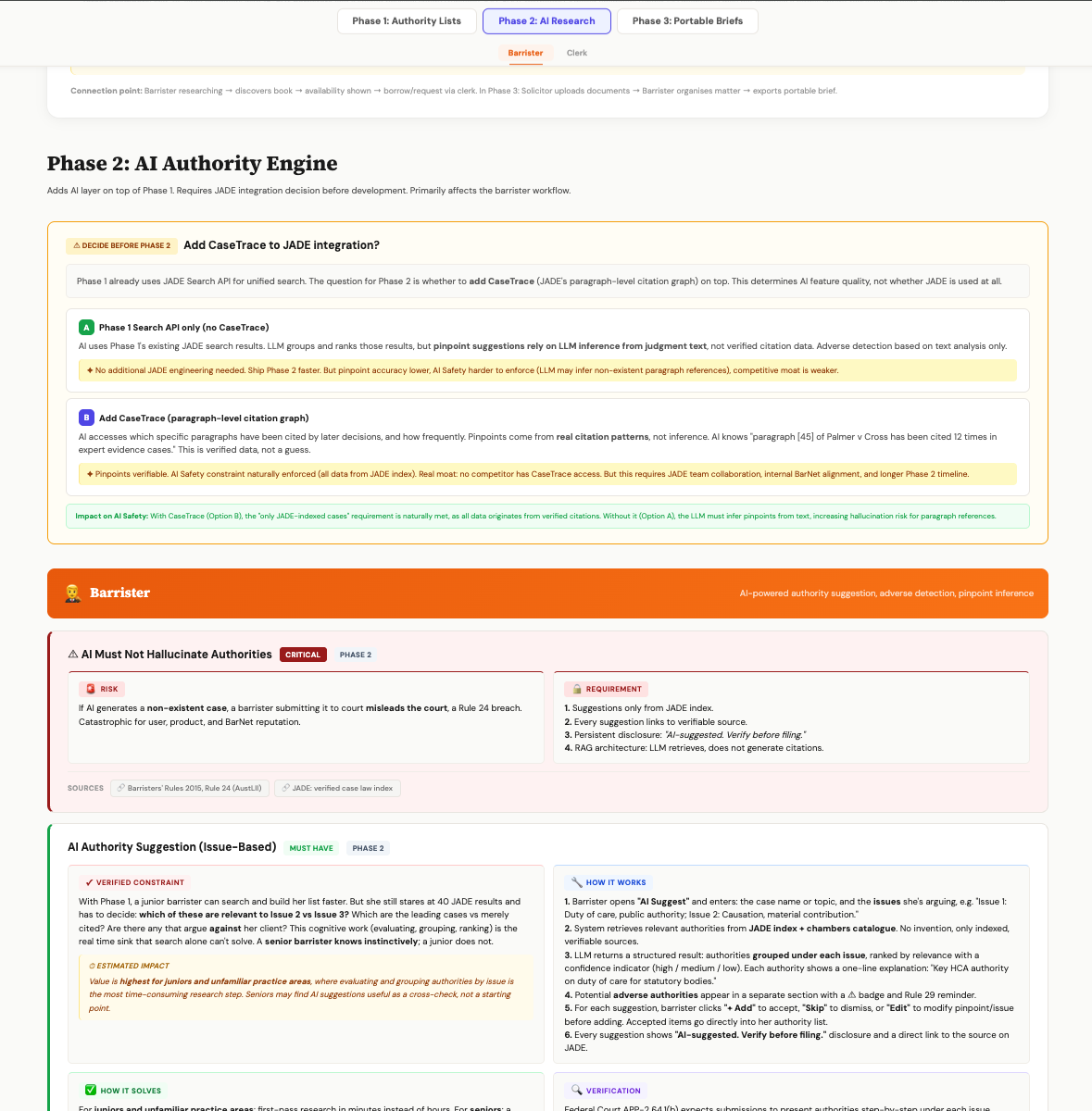
A data decision, not a UI decision
Phase 1 already uses JADE's Search API. For Phase 2 the question was whether to also integrate CaseTrace, JADE's paragraph-level citation graph, which knows which paragraphs have been cited by later judgements and how often.
I documented both paths with the trade-off explicit (speed versus verifiability), recommended Option B for the Rule 24 posture, and Open Law product agreed. The design works under either, but the spec ships against CaseTrace. When liability sits on the user, I default to architecturally defensible over cheaper, faster, looser.
Option A · Search API only
LLM groups and ranks search results, infers pinpoints from judgement text. Ships faster, but pinpoint accuracy is lower and hallucination risk is harder to constrain.
Option B · + CaseTrace
AI accesses verified paragraph-level citation data, not inference. "Paragraph 45 of Palmer v Cross has been cited 12 times in expert-evidence cases" is verified data, not a guess.
Phase 2 spec: Rule 24 framing, the CaseTrace decision document with both paths designed, and the four AI features built on top.
Rule 24: the constraint that shapes every Phase 2 decision.
Phase 1 stayed deliberately manual. The moment Phase 2 introduces AI, Rule 24 of the Barristers' Rules governs every decision: the barrister carries one hundred percent of the liability for what they file. An Australian Family Court judge has already publicly sanctioned a practitioner for citing a fabricated case the AI invented, and named JADE as the verification tool in her judgement: "A search of JADE reveals no such case." AI cannot be a defence.
So the design was never AI versus human. It was deciding what each is best at. Phase 2 turns that into architecture, starting from one principle: the AI cannot hallucinate authorities. Every decision in the spec below is downstream of it.
"AI cannot hallucinate authorities" is not a promise. It is seven layers of architecture.
Rule 24 puts one hundred percent of the citation liability on the barrister, so the system has to make hallucination architecturally impossible, not just unlikely. Seven layers work together so that no single layer carries the load alone. Each one closes off a different failure mode, and the next layer catches what the previous one missed.
The LLM searches and ranks. It never generates a citation. Every output corresponds to an entry that already exists in the index.
No external web, no training-data fallback, no free-text source. If JADE does not have it, the system returns "not found", never invents.
Every AI suggestion carries its JADE URL/ID inline. Provenance is structural, not optional. There is no place in the UI where an unsourced citation can live.
CaseTrace surfaces verified paragraph-level citation patterns. Pinpoint suggestions become facts in a graph, not guesses generated from judgement text.
Citations brought in from outside the system (other LLMs, drafts, colleague notes) get checked against JADE on upload. ✓ verified / ⚠ partial / ✗ not found. Fabricated citations get caught before filing.
The system architecturally cannot complete a filing without a human accept on every AI suggestion. No auto-apply, no batch acceptance. The accept action is the load-bearing primitive of Rule 24 liability.
"AI-suggested. Verify before filing." Sits next to every AI output, at the point of action, every time. Not a one-time onboarding modal. AI fatigue (the "I have seen this before" reflex) cannot remove it.
Layered defence beats single-line defence. If a barrister somehow brings in a fabricated citation that escapes Layer 02, Layer 05 catches it; if Layer 05 misses, Layer 06 forces a human accept where the misread is most likely to be caught. The Rule 24 problem reaches the court only if every layer fails simultaneously.
The boundary, line by line.
| 🤖AI does | 👤Human keeps |
|---|---|
| Search across the JADE legal index | Defines the issues to argue |
| Group authorities by issue, rank by relevance | Judges which authority actually helps the argument |
| Flag potential adverse authorities (Rule 29) | Decides how to distinguish or address them |
| Suggest pinpoints from citation patterns | Verifies the paragraph supports the proposition |
| Apply AGLC4 formatting against court template | Accept, edit, or reject every AI suggestion |
| Verify case and book citations on upload (cases against JADE, books against the catalogue) | Signs off, files, carries Rule 24 liability |
| Retrieve relevant chambers-held books by issue | Decides which textbook actually carries the argument |
| Surface book pinpoints and chapter cross-references from indexed text | Reads the passage to confirm it supports the proposition |
| Flag superseded editions and outdated textbook propositions | Decides whether the older edition still stands or the citation must update |
The AI takes the slow, repetitive, error-prone work, on both the case index and the chambers' book corpus. The barrister keeps the legal judgement, the verification, and the Rule 24 liability that travels with the filed document.
Built on the JADE + CaseTrace foundation, not on top of generic LLM output.
A junior barrister opens "AI Suggest" and enters the case topic and the issues she is arguing: "Issue 1: duty of care, public authority. Issue 2: causation, material contribution." The system retrieves only from the JADE index; the LLM groups results under each issue and ranks them with confidence.
Issue-based grouping is not decorative. It maps directly to Federal Court Practice Note APP-2, which requires submissions to present authorities issue-by-issue. The AI's output is already in submission structure.
Rule 29 (a different rule from Rule 24, and the distinction matters) imposes a positive duty to disclose binding authorities against your client's case. Senior barristers catch these through experience; juniors and anyone working cross-practice miss them. The AI analyses the argument direction and flags retrieved authorities that contradict or limit it.
Critical UX choice: framed as assistive detection, never guaranteed compliance. Persistent copy: "AI assists. Always verify independently."
The feature CaseTrace upgrades most dramatically. Without CaseTrace, the LLM infers pinpoints from judgement text: helpful, but inference. With CaseTrace, pinpoints come from verified citation patterns.
Same UI either way; the data backing it determines accuracy. This is why the CaseTrace decision is upstream of the UI.
Separate from authority-list building. A barrister uploads a submission or pastes drafted text; the system extracts every citation, checks each against the JADE index, and returns ✓ verified, ⚠ partial match with a correction, or ✗ not found. Directly addresses the fabricated-citation problem.
Clean commercial story: "What's your reputation worth? Every citation in the document gets checked against JADE before it reaches the court."
The same architecture extends to books, under the same privacy lens.
Books are working sources, not props. The JADE pattern (RAG over verified shared data, source-linked output, accept on every suggestion) extends naturally to the chambers' textbook collection, because the underlying logic is identical: retrieve from a verified index, never generate, keep the audit trail on the human accept. The privacy lens decides what is admissible: anything operating on shared catalogue or book content is fine, anything reaching into cross-user borrowing patterns is not.
Issue-grouped Authority Suggestion, applied to the chambers catalogue and book metadata. Same RAG pattern, different index.
CaseTrace-style suggestion against digitised TOC or full text. Verified pointer, not inferred page number.
Rule 24 catch-all extended to book citations on upload. Edition, page, and proposition checked against the indexed text.
Catches citations to older editions where the proposition has since been updated or the text superseded.
When a case is added to a list, surface the textbook chapters that discuss it, and the reverse. Corpus-level citation, not user behaviour.
When a JADE result cites a textbook the chambers actually owns, surface availability inline. Research and working library, one surface.
What stays blocked is anything that would re-create the strategy leak: "other barristers also borrowed", chambers-wide popularity, trending texts among colleagues. Those need cross-user usage data, and that data is clerk-facing only by Decision 05. The architecture admits the useful AI and rejects the leak-prone AI by construction.
The authority list is the brief's intelligence. The brief grows out of it.
In Australian practice a brief is the bundle a solicitor sends a barrister to take a matter into court: instructions, pleadings, evidence, correspondence, and the authorities the barrister intends to cite. Historically paper and ribbon. Increasingly digital. Phase 3 extends CLMS into this space, with a specific bet: the brief should grow out of the authority list, not the other way around.
The matter-level frame around it follows from the same bet. A matter typically runs across several stages (directions hearings, interlocutory steps, the final hearing, and often related proceedings on appeal). Phase 3 organises CLMS around the matter rather than a single hearing, so the authority list, the chambers' working library, and the Phase 2 AI surfaces all live in one place tied to the matter, not to a one-off filing.
Two directions into the same surface
The current incumbent in Australian digital briefs (Legal Ready, founded by Stephen Foley). A live collaboration platform around the brief itself: brief compilation, bundle indexing with court-bundle pagination, real-time annotation and tags, shared and private notes, secure delivery, and an AI assistant for document interrogation on the bundle. A user-curated library stores past authorities and submissions. Publicly documented integrations sit in the case-management space (Clio, NetDocuments, iManage, LEAP, Actionstep).
The architectural starting point is brief compilation. Authority research, citation formatting, and chambers operations sit alongside the product rather than inside it.
The starting point is the barrister building the authority list in chambers in Phase 1, with AGLC4 court-template validation, JADE-linked retrieval, and the Phase 2 AI safety architecture running on top: issue-grouped suggestion, Rule 29 adverse flagging, JADE-verified pinpoints, and citation verification on the full document. Phase 3 surfaces that working space as the matter, and the matter as the brief.
The architectural starting point is authority research. The brief inherits live AGLC reformat, JADE source links, and the AI safety surfaces by construction.
Three structural differences
The competitive case for Phase 3 turns on three structural differences, each of which is what Phase 1 and Phase 2 of CLMS were already building toward.
eBrief Ready's flow begins when a brief is compiled and shared. CLMS's flow begins earlier, when the barrister starts authority research in chambers. The brief is the artefact at the end of CLMS's workflow rather than the trigger at the start.
CLMS embeds JADE retrieval, AGLC4 validation, Rule 29 adverse flagging, and citation verification inside the authority list and the matter workspace. The barrister stays in one surface to search, cite, and verify; the brief inherits all of it.
CLMS ties the authority work to the chambers' physical book catalogue, loans, and availability. A barrister citing a textbook can see whether the chambers actually holds it, and the clerk's catalogue work feeds the same surface the barrister researches in.
None of this requires asserting what eBrief Ready does or does not do internally. CLMS earns the differentiation by what it puts inside the authority list and what it connects the authority list to. Extending from there into matter-level brief work is a smaller jump than building authority research and chambers operations into a product that started at brief delivery.
Scope
Whether Phase 3 ships inside CLMS as an extended surface or as a separate product sharing the same data is a roadmap question for Open Law product, not a design call I needed to finalise. The architectural constraints carry over either way: list privacy as design lens, accept-action audit trail, RAG-only AI.
Phase 1 proved the authority list as the working product. Phase 2 made it verifiable and AI-safe. Phase 3's bet is that the brief should grow out of that authority research core, with AGLC validation, JADE retrieval, adverse-authority detection, and chambers availability already inside the surface the barrister works on.
The depth is in the domain. The discipline is in the sequencing.
This project required understanding how Australian courts actually work: which templates they accept, how citations must be formatted, what happens when an authority is uncatalogued, and why a barrister's list is strategically sensitive.
Speed and depth were not opposed; they were budgeted. The product reframe (library → court-ready document) took a single session with Michael. AGLC4 italicisation, court-template differences, and the Part A/B/C structure were paid for in weeks because a misformatted citation is the kind of small error that costs trust with a barrister. Cheap calls stayed cheap, precise calls were deliberately slow, and the three-month Phase 1 window held.
The other call I would make the same way is the sequencing one. Shipping AI in Phase 1 would have generated more attention but less validation, and would have inherited none of the Rule 24 trust posture the manual workflow earned. Phase 1 stayed deliberately manual so that trust, privacy, the catalogue, and the court-ready output were already working before AI was allowed near a filing.
